©Copyright 2018 GEOSCIENCE RESEARCH INSTITUTE
11060 Campus Street • Loma Linda, California 92350 • 909-558-4548
A protein is composed of a sequence of smaller units called amino acids. About 20 different amino acids are used in making proteins, and the sequence of amino acids is crucial to the structure and function of the protein. The sequence of amino acids in a protein is determined by information stored in the DNA. DNA is composed of a sequence of smaller units called nucleotides. Each amino acid is paired with a set of three DNA nucleotides, called a codon. The sequence of codons determines the sequence of amino acids in the protein.
In constructing a protein, information from DNA is copied into messenger-RNA and used to build the protein. If a mistake is made in copying the information, it changes one codon to a different one. This can change the amino acid that goes into the protein at that point, and this can change the nature of the protein. However, some DNA codons specify the same amino acid, so some DNA changes do not change the amino acid sequence of the protein. Codons that are equivalent in this sense are said to be synonymous. A change in a DNA codon that has no effect on the amino acid sequence is called a synonymous substitution.
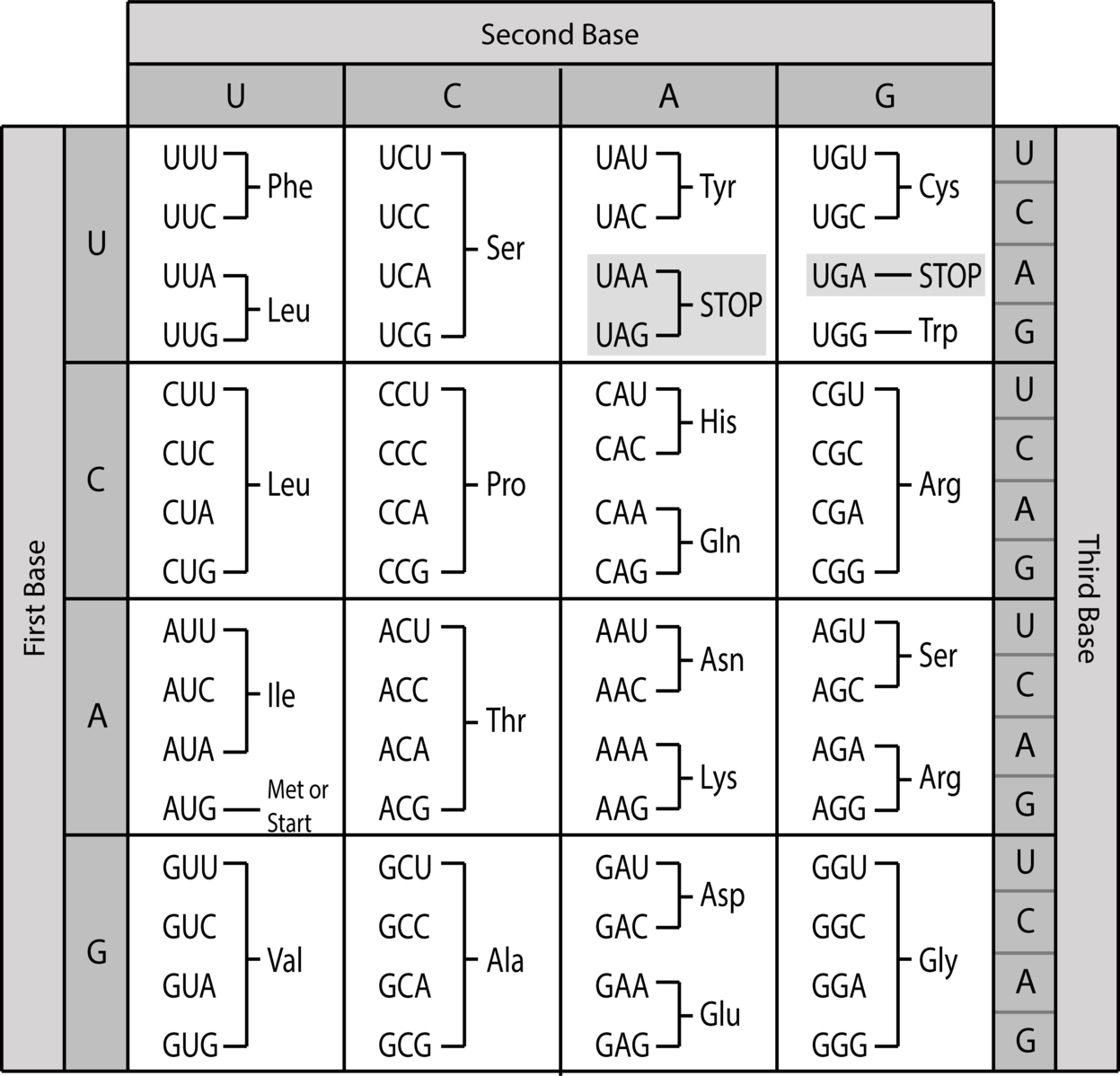
The genetic code. Brackets indicate codons that are synonymous (see text).
Image: Sarah Greenwood; CC by SA 4.0
Synonymous substitutions have been assumed to have no effect on an organism. However, a report[1] of research on the bacterium E. coli shows that this may not always be true. A protein has a particular shape that depends not only on its amino acid sequence, but also on how the molecule folds into its specific shape. Mistakes in folding cause malfunction of the protein. According to the report, protein folding is affected by synonymous substitutions. This means that codons play a role in protein folding as well as in determining the amino acid sequence, and DNA differences that appear insignificant might actually be quite important,
This discovery could have some interesting implications. If synonymous codons have functional differences, they could be useful in studying the relationships among similar species. Two species could share a particular codon for functional reasons rather than due to common ancestry. If closely related species are distinguished by different but synonymous codons, this could indicate that differences in the codons have contributed to species differences. Such possibilities are speculative at this point, but they do serve as a reminder that what everyone knows today may change tomorrow.
James Gibson, PhD
Geoscience Research Institute
References
[1] Walsh, IM, MA Bowman, IFS Santarriaga, A Rodriguez, PL Clark. 2020. Synonymous codon substitutions perturb cotranslational protein folding in vivo and impair cell fitness. Proceedings of the National Academy of Sciences 117(7):3528-3534. https://www.pnas.org/content/117/7/3528