A CRITIQUE OF CURRENT ANTI-ID ARGUMENTS AND ID RESPONSES
by
Leonard Brand
Professor of Biology and Paleontology, Loma Linda University
ABSTRACT
Intelligent Design (ID) presents empirical evidence to support its contention that origin of the complexity in biological systems requires input of intelligence. Many scientists reject ID or any other explanation for origins that does not utilize only naturalistic principles. There have been a number of carefully written books and articles arguing that ID has failed to make its case. ID advocates have published responses to these arguments. Which of these lines of argument is most convincing, when compared to what is known about living systems? This paper evaluates a representative sample of the best anti-ID and pro-ID publications and presents a conclusion as to the present state of the evidence and arguments regarding these positions.
Non-materialistic concepts of origins have generally included belief that the universe is the result of intelligent design. However, in the last two decades the term “intelligent design” (ID) is commonly used for a specific movement developed by a group of highly educated scientists and philosophers. The movement began in the 1980s (Thaxton et al. 1984; Denton 1985) but was first brought to public attention by publications of Phillip Johnson, a law professor in the University of California. The first of these was Darwin on Trial (1991), followed by other books (Johnson 1995, 1997, 2000).
The ID movement does not concern itself with the age of the earth, flood geology, or evolutionary history, but focuses on how life originated and the origin of biological complexity. Design theorists see reasons for believing that life is the result of intelligent design, rather than a materialistic process. In other words ID is not a comprehensive view of origins or of the relationship between faith and science. It doesn’t address questions about the supernatural or other religious questions. It also doesn’t concern itself with the identity of the designer. Individual ID proponents may express their personal views of such matters, but ID ideally addresses just one point: purely empirical arguments indicate that the complexity of life requires intelligent design. This is the only aspect of ID that we will consider. This view has been developed in books written by leaders of the movement (Behe 1996, 2007; Dembski 1998, 1999, 2002, 2004, 2006; Dembski & Kushiner 2001; Dembski & Wells 2008; Meyer et al. 2007). A book edited by Dembski and Ruse (2004) contains chapters for and against ID.
In recent years the controversy over intelligent design has been heating up, and the number of publications on both sides of the debate has increased. An important stimulus for all this recent activity is the political controversy over what will be taught in public school science classes (Pennock 2003). I will not speak more about political matters of science education in public schools, but will focus on the scientific and philosophical issues behind the choice between naturalistic origins and intelligent design.
PHILOSOPHY OF SCIENCE
The modern scientific method uses the philosophical approach called methodological naturalism (Scott 2004). Methodological naturalism (MN) does not make any claims about whether or not God exists or whether there is such a realm as the supernatural. Methodological naturalism is simply a practical rule, the most important rule in the contemporary definition of science. The rule is that science does not ever invoke the supernatural in its explanations, but attempts to see how far it can explain phenomena in the universe by strictly physical and material causes (Scott 2004). In most of science this rule works well and the “game” of science defined by this rule has resulted in unprecedented scientific progress. Even ID is not in conflict with MN part of the time. An exquisite set of “laws of nature” governs the universe, and these reliable, unchanging laws allow us to discover much about how the universe and life functions, and how life changes and adapts to changing conditions. ID does not try to determine whether these laws have a supernatural origin.
A related view is philosophical (or metaphysical) naturalism, the idea that there is no god and no supernatural forces, and the entire universe is the result of material causes, the laws of physics and chemistry.
Controversy begins when we deal with the origins of life and of the universe. Some suggest dividing science into operation science and origins science (Thaxton et al. 1984). Operation science is the study of the functioning of the physical and biological universe, the study of regularlyoccurring processes. Origins science (including ID) is the study of singular, unique events, primarily the origin of the universe and of the initial life forms. In this scheme operation science uses the concept of MN, while origins science may include postulation and evaluation of explanations based on intelligent design.Mainline science does not accept ID as science, but expects that all of science will be subject to the rule of MN. When advocates of ID object to the arbitrary exclusion of design by the philosophy of naturalism, a common response is that science uses MN, not philosophical naturalism, and MN makes no claims about the existence or nonexistence of any designer (Pennock 2004). MN allows the existence of God, but just doesn’t use that concept in its explanations of nature. Ideally that may be true, but in practice the boundary between the two types of naturalism becomes blurred, because scientists who use either type of naturalism do not allow consideration of any intelligent design (supernatural or otherwise) to influence scientific thinking, even in origins. MN may seem neutral and openminded, since it ideally does not make any claims about the existence of God or other possible sources of design. However, many scientists who use this approach are, in practice, adamantly opposed to consideration of any form of intelligent design. The ultimate result, in practice, is that MN and philosophical naturalism have essentially the same effect on the discussion of origins. They rule out any reference to design, irrespective of the evidence.
EVALUATING THE ARGUMENTS
Philosophy professor Del Ratzsch (2001) has written a book evaluating the scientific legitimacy of intelligent design, from the perspective of the philosophy of science. He concluded that there is no compelling basis for excluding intelligent design from being explored within the scientific context. However, the scientific community has been very vocal in its criticism of intelligent design (ID). A general scientific conclusion is that the Neodarwinian mechanism of chance (random mutations) and necessity (natural selection preserving the biological variations that favor survival) are sufficient to explain the biological world, and thus design “as a fundamental principle disappears” (Young & Edis 2004). But whether chance and necessity can explain the origin and the diversity of life is a very big question —THE question under discussion here. We will frequently return to this question in our discussion.
Edis (2004a) concludes that ID is not excluded from science on a philosophical basis, but that ID is not taken seriously because it is not scientifically successful, while science under MN has been very successful, and chance and necessity are adequate explanations for nature. However, I suggest that although MN has been a very successful approach in most areas of science, the success of MN in explaining the origin of life and the origin of significant new biological structures has yet to be demonstrated. It also appears that in many cases ID is excluded or opposed on philosophical grounds.
We will evaluate a number of arguments from both sides of this issue and attempt to reach a conclusion on the relative scientific merits of ID and origins research under MN, as currently understood. We will examine current arguments and tactics being used against intelligent design and the responses of those who doubt the adequacy of naturalism. How convincing are these arguments, and how solid are the responses to the arguments? This paper is not a comprehensive literature review, but samples a number of what I consider to be the best quality recent books and articles on this topic, to provide an overview of the controversy.
My goal is to be fair to all parties, and recognize weak or strong arguments, no matter who uses them, or whether I agree with the author’s conclusions. We don’t need to be afraid of data or of careful thinking. We may struggle in our attempts to understand and respond to some interpretations of evidence, but in the end truth will stand on its own.
Biological information
It is often just assumed that since chance and necessity are sufficient for some types of organization in nature (e.g., snowflakes, crystals, and hurricanes), they are sufficient for biological origins. But arguments against ID will have to deal with the origin of biological information, and whether chance and necessity are sufficient for the job.
A protein, e.g., a hemoglobin molecule, consists of a sequence of amino acids joined together in a chain. A protein is not a repetition of a simple sequence, as in a crystal (e.g., ALV ALV ALV ALV ALV), but is complex and non-repetitious. It is also specified, which means that for the molecule to be functional the amino acids in at least part of the molecule must occur in a specific sequence. This complex, specified sequence of amino acids contains information, like the sequence of letters on this page. William Dembski calls this complex, specified information (CSI) (Dembski 1999), and argues that proteins and the information in books (CSI) are too complex to arise by chance, without intelligent input. The same concept applies to the sequence of nucleotides in nucleic acids, DNA and RNA. The origin of this biological information (CSI) in proteins and nucleic acids is the single most significant challenge for any naturalistic theory of biological origins.
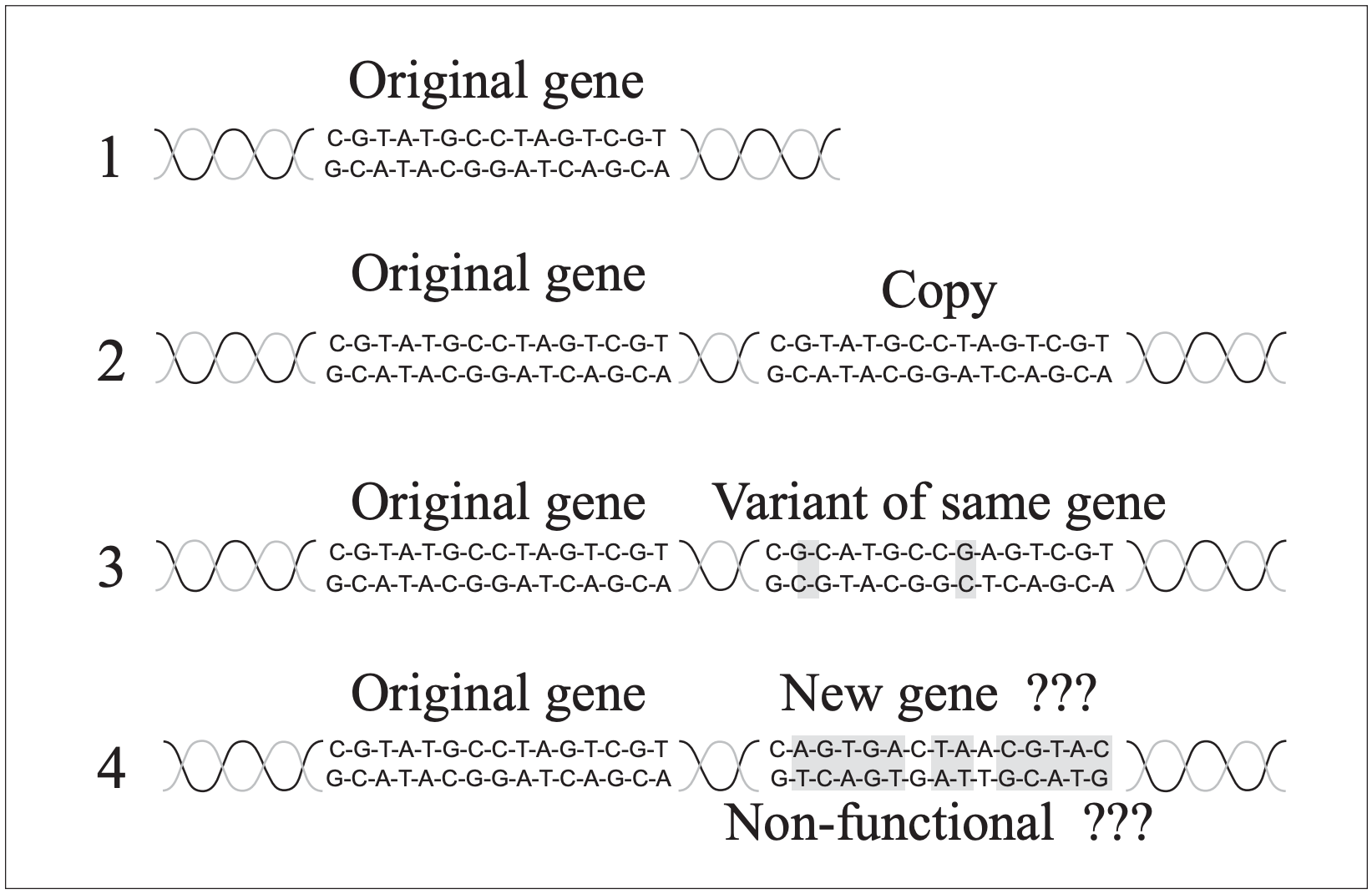
The proposed process for naturalistic evolution of new biological information and new genes begins with mutational duplication of genes, producing excess genetic material that could then be modified by more mutations and eventually become new genes coding for new proteins(Fig. 1). Much of the genetic material in organisms consists of “silent DNA” (including pseudogenes [Gibson 1994]) with no known function. This silent, non-coding DNA is usually interpreted as junk DNA, which includes the nonfunctional, duplicated genes that can evolve into new genes. After reviewing arguments for and against ID we will consider whether this theory of gene duplication and evolution is an adequate explanation for the origin of new biological information.
Irreducible complexity
Michael Behe (1996) argues that irreducible complexity is evidence for intelligent design. A system (generally a “molecular machine” or a physiological system) is irreducibly complex if it contains at least three or more parts that are critical to its functioning, and it can’t work unless all critical parts are present at once. A system that is truly irreducibly complex couldn’t arise by evolution, because evolution can only produce a complex system by adding to its complexity one small step at a time. Meanwhile the system must be functioning during the entire process, or natural selection will be likely to eliminate it. Behe argues that some biological systems are irreducibly complex, and cannot evolve because all critical parts would have to appear at the same time (Behe 1996).
Behe uses a mousetrap as an analogy, an example of a mechanism that doesn’t work if one part is missing, and thus could not evolve, even
Figure 1. The theory of genetic evolution by gene duplication.
if it were alive. Some have responded by figuring out ways to modify a mousetrap so it can have fewer parts and still work, at least theoretically (Young 2004), and could evolve into a more complex mousetrap. I don’t know if anyone has tried to catch mice with these modified traps.
Behe (2004) analyzes these suggestions that a mousetrap is not irreducibly complex. The problem is that the “simpler” mousetraps must be intelligently adjusted before they can become parts of a complex trap. At some steps additional parts (e.g., staples) must be added in a precise way before two simple traps could be combined. There seems to be too much requirement of intelligent action or chance for this to be a viable example of the Darwinian process.
Behe presents the bacterial flagellum as an example of an irreducibly complex system. The flagellum is a slender tail-like structure, with a motor that appears, with electron microscopy, amazingly like an electric motor. The flagellum is rotated by the motor and acts like a propeller to move the bacterium along. A sensory system detects the chemical environment around the bacterium, and stimulates the flagellum to rotate one way to go forward, or rotate the other way to reverse direction. Many protein molecules, of specific structure, compose the flagellum and its motor. A number of these must be there, all at once, for the flagellum to function at all. If so, how could it evolve step by step? This same argument has been applied by ID proponents to the eye, the blood clotting system, and other biochemical systems.
Challenges to irreducible complexity
Some authors have challenged Behe’s interpretation of the flagellum (e.g., Miller 1999, 2004; Ussery 2004; Musgrave 2004). They point out that there can be much variation in the sequence of amino acids in the flagellum proteins, and that the structure of the flagellum varies in different types of bacteria. Some flagella are simpler in structure than those that Behe describes. This, they argue, shows that the flagellum can start out simple, and evolve more complexity, step by step.
The above authors also emphasize the similarity between parts of a flagellum and other bacterial components. Some bacteria utilize a long flagellum-like structure that doesn’t turn like a propeller, but repeatedly attaches to a surface and pulls the organism along. Flagella are also structurally very similar to hollow flagellum-like secretory organs which secrete protein solutions through their hollow tubes, in some cases to attack the cell walls of host organisms. It is then argued that the individual parts of a bacterial flagellum evolved for some other function, like secretion, and the complex flagella that Behe discussed evolved by co-opting parts from these other systems, and combining them in new ways to evolve a flagellum with a new function. According to this hypothesis, the problem posed by irreducible complexity is solved by indirect evolution of a flagellum. It is indirect because the parts are evolved for other functions, and only then are they combined, step by step, to make a flagellum. This evolution of parts for one function, followed by co-opting of such parts for a new function has been called exaptation (Gould & Vrba 1982).
This same logic is often used in explaining the evolution of other biological systems. Many proteins are composed of sub-units, or domains, and each domain may be used in other proteins. This observation has suggested the theory that various protein domains can evolve, each in response to some selective force, for a particular function, and then these domains can combine in different ways to make many types of proteins. In this way mutation and natural selection may generate relatively simple domains, which can combine to form proteins with whole new levels of complexity and diverse, novel functions.
In the ways described above, it is proposed, it would not be so difficult to evolve complex systems and organisms, by evolving simple components and combining them in new ways to make new complex structures. Miller (2004) maintains that the existence of simpler systems consisting of components of the flagellum indicates the collapse of Behe’s concept of irreducible complexity as an argument for design.
This proposal may sound good, but those “simple” protein domains and alleged co-opted parts are not necessarily so simple. And the origin of these “simple” components which have the ability to reorganize into such complex, functional systems also requires an explanation.
The theory of co-option of parts for new functions can be compared to the use of Lego® building blocks. A few simple Lego® parts can be put together to make a great variety of complex structures. This is possible because the blocks were carefully engineered with this goal in mind. Proteins are orders of magnitude more complex than Lego® structures. If protein domains show the engineering that allows combining them into a wide variety of proteins with differing functions, this ability increases, rather than decreases, the complexity of the problem for evolution. Natural selection cannot see what will be needed in the future, and cannot be expected to design protein domains with the engineering to combine in many novel ways to make proteins needed for new, complex functions that will arise in the course of future evolution.
Behe (2004) points out that finding, for example, subunits of a flagellum that are functional without being part of the most complex flagellum does not argue against the validity of irreducible complexity. Many of these subunits are likely to have an irreducibly complex core, and this needs an explanation. Behe (2004) describes some additional challenges for the origin of a complex structure like a flagellum, that go beyond the structure of the flagellum itself. It has an intricate control system, and an elegant assembly process, and these may be part of the irreducibly complex whole. Also, if parts of other systems are to be co-opted to become combined into a flagellum the parts can’t necessarily just be popped together — they must be adjusted so they will fit together. These factors multiply the challenge of making a complex structure without a designer.
A recent paper in Science (Bridgham et al. 2006) is claimed to exemplify studies that “solidly refute all parts of the intelligent design argument (Adami 2006). The research started with a protein that had the ability to strongly interact with three steroid hormones, and then modified it to make it resemble their interpretation of what the ancestral hormone must have been like. This modification involved two amino acid changes in the protein. It still interacted with the steroids, but more weakly. It was then argued that they had reproduced the evolutionary sequence that led to the protein complex. Behe’s unpublished response (internet) is that 1) the system Bridgham et al. studied was not even close to being irreducibly complex, 2) the simple change in two amino acids was easily within the range of variation consistent with ID, 3) nothing new was produced, but they only weakened the ability of the protein to bind to several molecules, and 4) this was the “lamest attempt yet...to deflect the problem that irreducible complexity poses for Darwinism.”
This entire Darwinian process for generating complexity needs one important component to make it viable — a mechanism, a biochemical process capable of making the needed transitions from one level of complexity to another by purely material causes. Is such a process known? This question is pertinent to the other arguments presented below, and later we will attempt to answer the question.
Redundancy
Shanks and Joplin (1999) argue that there is redundancy in biochemical systems that negates irreducible complexity. For example they discuss the chemistry of glycolysis, part of the process that produces usable energy within cells. If Behe’s mousetrap model was correct, then using some laboratory procedure to knock out one enzyme from the glycolysis pathway should stop the whole system. However that doesn’t happen. There is redundancy in the system, so if one enzyme is taken out another enzyme performs the task and the process goes on. This redundancy exists, they say, because of gene duplication. A gene that produces an enzyme becomes duplicated by a mutation. One of the duplicated genes carries on its usual function, and the duplicate mutates until it is co-opted to produce a new enzyme with a novel function. The new enzyme may not be as efficient, but evolution presumably can improve its efficiency. This redundancy means there are multiple routes to accomplish a biochemical task. If one route fails, another takes over. This shows, they say, that Behe’s simple mousetrap illustration of irreducible complexity is not a correct description of biochemical reality in living organisms.
Behe (2000) responds that some biochemical systems are redundant, but some are not redundant. He describes, e.g., some proteins in the blood clotting system that are not redundant. If they are missing it is lethal. There are some additional, pertinent issues that Behe didn’t discuss. If there is as much redundancy as Shanks and Joplin claim, then the biochemical systems are actually more complex and thus more of a challenge to evolve, than if they weren’t redundant. The redundancy provides a safety net in case of mutational damage to part of the system, but if there was no intelligent design, all of that complexity had to evolve. And if the biochemical pathway evolved, it isn’t likely that it was redundant from the beginning, but went through a non-redundant step. In addition, the assertion that novel features evolved through gene duplication involves an assumption that we will discuss below.
Some biochemists also point out (Boskovic personal communication) that the presumed redundancy in, e.g., blood clotting, is not really redundant. The alternate pathways are not optional, but form a network of reactions which assures the right response in various circumstances. Engineers regularly use redundancy as a method of ensuring functional design. Redundancy is completely compatible with biological design, and actually introduces another level of complexity that perhaps increases the challenge for a naturalistic theory of origins.
Shanks and Joplin (1999) do seem to be correct in saying that the mousetrap analogy is not adequate for comparison with redundant systems. This doesn’t invalidate the mousetrap analogy, however. Simple analogies generally do have limits in their application. Perhaps the blood-clotting cascade is better represented by a series of mousetraps. If one trap fails, the mouse will encounter the next traps.
Self-organization and the origin of biological complexity
Shanks and Karsai (2004) tackle the origin of complexity by pointing out that complexity and organization exist on all scales — in the shape of galaxies, hurricanes and snowflakes, and in molecules and organisms. They propose that this complex organization is best explained by processes of self-organization, rather than as intelligent design by a supernatural being. The same argument is also presented in Shanks and Joplin (1999). They describe how, if the necessary components (atoms, molecules, organisms, etc.) are present, and there is energy exchange with the environment, self-organization can occur. An example is the interaction of air and water molecules and heat, in the proper context, to organize itself into the complex spiral patterns of a hurricane.
Do these arguments demonstrate the superiority of MN over ID, as explanations of the origin of biological systems and organisms, as the anti-ID writers maintain? Actually there are at least two classes of phenomena used in explanations of origins. The first class includes snowflakes, and the shape of hurricanes and galaxies. These are purely physical phenomena, governed by laws of physics. As water freezes under the right conditions it makes the intricate, organized shapes in a snowflake. A snowflake has an intricate shape, it exhibits contingency (it could be in some different shape), and someone without knowledge of chemistry and physics could think of the symmetry and shape of a snowflake as a type of specification requiring intelligent design. However, science knows much about chemistry and physics, and it is evident that there are physical reasons for the design features common to all snowflakes (Edis 2004b).
According to Dembski the nature of the complexity in living things is unique, “capturing the notion that there is something in life that is different from the intricacy of a snowflake.” But Edis (2004b) doesn’t accept Dembski’s logic, that there are fundamental problems with the comparison of snowflakes and biological design. On this point Dembski is right and Edis is missing something significant. Living things require biological information (the sequences in proteins and DNA) for their existence and their design, while snowflakes have no such information. The shape of a snowflake is evidently determined by chance and necessity — necessity in the form of basic laws of physics controlling the crystallization process in freezing water, and chance that allows the specific snowflake to vary randomly. Within the necessity of the physical laws governing the general hexagonal shape of snowflakes, there is no limit or function to the intricate details of crystal pattern — they can vary at random, with no specificity.
As a hillside erodes from the runoff of rainwater, the water flow and erosion occur within limits determined by gravity. Within those limits there are details that can vary in a random pattern. This is comparable to the shape of a snowflake — there is no specified and complex information involved. It is truly chance and necessity; and it doesn’t matter what the exact pattern is. The same seems to apply to the shape of hurricanes and galaxies. The nature of biological information, the other class of phenomena pertinent to issues of origins, is fundamentally different from the forces controlling the formation of a snowflake.
In contrast to a snowflake, the sequence of amino acids or of nucleotides (i.e., biological information) is specified, complex information; and it does matter what the sequence is. What is the origin of this specified, complex information? Are chance and necessity adequate to produce the biological information in living systems, or is ID required? So far in this discussion we have not arrived at an answer to that question, but we will get to it. Edis’s discussion of snowflakes, hurricanes, etc., misses the point entirely because he doesn’t recognize the unique complexity and specificity of biological systems.
One other example of self-organization is the Belousov-Zhabotinski (BZ) reaction. In this chemical reaction several chemicals (an organic substrate, an acid, bromate ions, and transition metal ions) are placed in a beaker, and the system self-organizes to perform a repeating cycle of reactions, with a sequence of associated color changes repeated in each cycle. It has been argued that the BZ reaction involves organized, irreducible complexity without the need for any intelligent designer. This reasoning is then extended to suggest that these reactions illustrate how life could arise by self-organization (Shanks & Joplin 1999; Shanks & Karsai 2004).
But there seem to be some problems with this conclusion. Are BZ reactions really illustrations of irreducible complexity “without any help from intelligent designers?” What about the chemists who understand the principles of chemical reactions and use this knowledge to put the right chemicals in a beaker? I am not aware of any natural occurrences of BZ reactions, without intelligent intervention by chemists, but even if they do occur, there is still another problem. Like the shape of snowflakes, these reactions are controlled by basic natural laws and do not involve anything comparable to biological information, whose origin would have to be explained by something apart from laws of physics and chemistry. Another criticism is that the BZ reactions do not require very specific chemicals, as long as there is an organic molecule that can be oxidized, the right category of metal ions, etc. (Behe 2000). BZ reactions also do not produce anything durable, like biological information.
Behe (2000) suggests that even though the chemicals needed in a BZ reaction are not specific enough to qualify as irreducible complexity as exemplified in biological systems, BZ reactions are comparable to the self-organizing properties in, e.g., a tornado.
Behe gives the blood clotting cascade as a better example of irreducible complexity, because at least some of the proteins involved require a very specific structure in order to work. The simple chemistry of BZ reactions is not comparable to the sophisticated biochemical machinery in living cells. He also points out that even though mathematical models of the chemical behavior of BZ reactions and biological systems may be similar, the underlying chemistry is very different — one does not explain the other, and the BZ system does not explain the origin of biological systems. Shanks and Joplin (2007) attempt to sum up their reasons for rejecting Behe’s arguments, but this response relies on the same type of superficial logic as their previous articles.
Self-organization and the origin of life
BZ reactions could be considered a suitable analogue for the origin of biological information if the necessary components for life were mixed in a beaker and a living system, or parts of a living system spontaneously arose, as the cycling reactions arise in a BZ reaction. If the appropriate elements are mixed together in an apparatus simulating the presumed atmosphere on the primitive earth, amino acids and other biological molecules spontaneously form. This demonstrates that the formation of amino acids and nucleotides can form by a “self-organizing” process, at least partly analogous to what happens in a BZ reaction. But these are only the “bricks” that must then be arranged in the proper sequence to form proteins and DNA/RNA, the biological information molecules. The “selforganization” of life cannot be claimed until the amino acids and nucleotides are arranged in the correct sequences to form biologically functioning macromolecules (i.e. biological information) and biochemical machines to form a cell. So far that has not been demonstrated in any experiments.
A likely response to this statement is that we should not expect such a clear-cut result in the short time we have to work on it. That may be so, but it remains true that acceptance of the hypothesis that life arose by a naturalistic process can only be accepted on faith. A person who accepts MN will likely think it is worthwhile continuing the scientific search for the naturalistic mechanism of the origin of life. One who believes the origin of life is impossible without intelligent design should not condemn origin of life study as bad science, but he/she is likely to think that their scientific effort is better utilized on a different topic, because origin of life research, for biochemical reasons, is a dead-end road.
Natural selection could not help assemble the initial functioning biological information, because natural selection could not function at all until there was a living, reproducing organism. Only when there are living organisms can there be variation in individual characteristics and different likelihoods of survival and reproduction, and a genetic system to preserve the characters of those favored by natural selection. Consequently, before the first living things existed the only mechanism for assembling a set of functioning proteins and nucleic acids appears to be chance. Richard Dawkins, speaking of the origin of life (1986, p 141), summarized it nicely: “What is the largest single event of sheer naked coincidence, sheer unadulterated miraculous luck, that we are allowed to get away with in our theories, and still say that we have a satisfactory explanation of life?” That may seem satisfying to some, but is it worthy of being called science?
Algorithms and weasels
Mark Perakh (2004) challenges Dembski’s use of certain algorithms in his arguments that complexity cannot be purchased without intelligence. These are detailed analyses, and it would be instructive to see Dembski’s response to Perakh. There isn’t any special reason to think that either the ID proponents or the opponents of ID have all the answers. There will no doubt be an ongoing discussion over the details.
One of Perakh’s criticisms of Dembski, however, is clearly wrong. Perakh objects to Dembski’s conclusion that an algorithm used by Richard Dawkins (1986) is fallacious. Dawkins enters a sentence (METHINKS IT IS LIKE A WEASEL) into a computer simulation, scrambles the letters, and then allows the simulation to recreate the sentence through random changes in the sequence of letters and a selection process to choose between the previous letter sequence and the mutated sequence. By this process his simulation of mutation and natural selection fairly quickly reaches the original sentence. Dembski doesn’t accept this as a legitimate simulation of evolution. Perakh vehemently insists that Dembski is only criticizing minor issues in Dawkins’ simulation, and that the simulation is indeed a good example of evolution. Is Perakh’s criticism valid?
The problem with Dawkins’ simulation is that the computer compares each mutated letter sequence with the “target,” which is the actual sentence METHINKS IT IS LIKE A WEASEL. If the mutated sequence is closer to the target, the computer chooses the new letter sequence. The problem here is that the actual biological evolution process does not know what the “target” is; it does not know what features will be needed in the future. Natural selection can only choose between an existing feature and a mutated alternative on the basis of their selective value at that moment in time. It can only determine which color moth will be more camouflaged today. It cannot look into the future to see what the evolution process is aiming for — what color the moths will need to be a few years from now. Evolution’s lack of foresight is not an idea made up by ID advocates, but is a fundamental concept in the theory of evolution. Dawkins’ simulation does not model Darwinian evolution, but illustrates only one point — it shows that mutation and natural selection can work effectively if there is intelligent guidance of the process. It illustrates nothing beyond this. Dembski was not criticizing a minor problem; Dawkins’ simulation contains a very major flaw. It is astonishing that Dawkins published this simulation in the first place, and that knowledgeable scientists still refer to it favorably.
Social wasps and “intelligent action”
Social wasps build complex nests composed of hexagonal cells packed tightly together. Such a structure seems to require sophisticated cognitive ability to produce. But research has shown that nest-building by wasps is not the unfolding of an intelligent plan, and there is no wasp supervisor who manages the building. Rather each wasp follows several simple rules, and applies the rules in response to the conditions it encounters at each step in the building process. Thus without any mental blueprints or supervised planning a complex structure emerges as a by-product of application of the simple rules. There is no requirement of “intelligent design from outside the system,” and the “orderly, complex structures emerge as the consequence of the operation of blind, unintelligent, natural mechanisms operating in response to” the local nest-construction environment (Shanks & Karsai 2004).
Their conclusion overlooks some important concepts. It took a group of scientists much intelligent research to figure out the “simple” rules, which aren’t so simple after all, and the results of the rules are indirect. The constructive result of an individual move by a wasp only becomes evident as it fits into the overall context of many additional moves by many wasps, following the same rules. If wasps evolved, those sophisticated, indirect rules had to be determined and programmed into the wasps’ brains somehow. Are random mutation and natural selection up to the task? Or would such indirect rules only exist if put there by design? We can’t demonstrate that this system can’t arise by evolution, but these authors are only exercising faith in their chosen philosophical framework. Their claim that no “intelligent design from outside the system” is needed to supply the wasps with the necessary nest-building rules is simply a statement of their faith, with no supporting evidence. This is one more illustration of how the anti-ID arguments often miss the point entirely.
Word pictures as explanation
Word pictures of how a complex structure could evolve often sound quite convincing. But is reality as simple as the word pictures make it sound? Is there good reason to believe that the evolution of the eye, or bird flight, or a flagellum is convincingly demonstrated by these word pictures of proposed evolutionary steps, exaptations, and recombinations of protein domains? It is often implied that the evolutionary scenarios (word pictures) presented are adequate to eliminate the need for ID (e.g., Young & Edis 2004).
But theoretical descriptions of how a set of evolutionary steps can evolve new structures depend on the assumption that this process will actually happen, or has happened. Word pictures, or just-so stories, as they are sometimes called, make evolution of novelty sound easy, but they don’t deal with the fundamental biochemical problem of how new biological information arises. Young (2004) describes the use of a genetic algorithm to show how all the types of eyes can evolve, and then says that the existence of a variety of eyes provides hard evidence to support this claim. He states that “If the genetic algorithm can generate complexity, then so can evolution by natural selection.” Even if such an algorithm models some aspects of evolution, it does not demonstrate that the correct mutations will in fact appear when needed, providing the raw material for natural selection to successfully invent the next more complicated type of eye. It is also far from obvious that each intermediate step from one type of eye or other structure to another will have some improved survival value, and would be selected, rather than rejected, by natural selection. We will still return to this crucial issue later, but there are a few other items to deal with first.
God-of-the gaps: has the gap been filled?
The ID claim that some organs or biochemical systems are too complex to evolve is often called a god-of-the-gaps argument; since we can’t imagine how they can evolve (the gap in our knowledge), they must require a designer. It is claimed that we know enough about how complex features evolved to make ID unnecessary (the gap has been filled). A classic case is the eye. The vertebrate eye is amazing in its complexity, but is it irreducibly complex? Young (2004) says no. In the animal kingdom there are a great variety of eyes, including simple light-sensitive spots, and various simple eyes that provide different levels of visual ability. Young and authors he references claim that these eyes can be arranged in a sequence illustrating convincingly how eyes evolved, and eliminating the need for a designer for the origin of eyes.
The origin of flight in birds is another example of the same concept (Gishlick 2004). It is hard to imagine how the power of flight in birds could evolve — “what good is half a wing?” The counter-argument given here is a comparison of forelimb structure in the dinosaurs presumed to be bird ancestors. These bipedal predatory dinosaurs can be arranged in a sequence showing changes in the wrist allowing movement of the forelimb in prey-catching maneuvers that were, it is proposed, later exapted for the purpose of flight. Add to this the apparent existence of feathers in some dinosaurs (presumably for insulation) (Martin 2001, p 249; Norell et al. 2002), and it is claimed that we now understand the origin of flight, which is first seen in the fossil bird Archaeopteryx.
However, there is of course a huge gap, not represented by fossils, between the non-flying dinosaurs and the flying Archaeopteryx, and this gap includes all the steps in the presumed evolution of flight from nonflying but perhaps feathered dinosaurs. This example, the proposed evolution of eyes, and many other cases share a significant problem, which we will now address.
Gene duplication and the evolution of new genes – a response
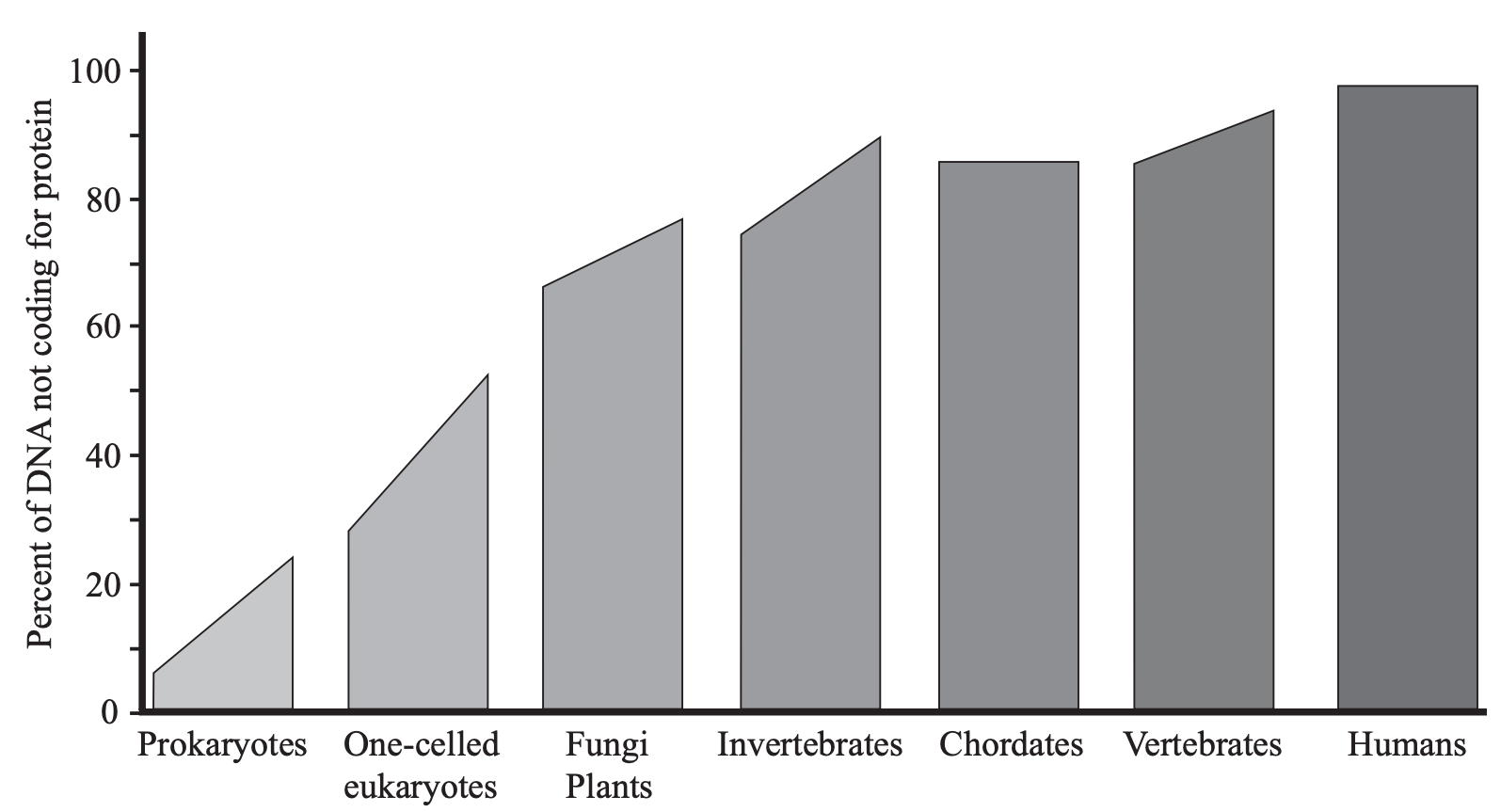
New genes are assumed to arise by gene duplication, producing extra genes, and evolution of new genes occurs within this junk DNA. But it is being recognized now that more of the “junk DNA”, including pseudogenes, is functional than previously had been thought (Reynaud et al. 1989; Nowak 1994; Ochert 1999; Hirotsune et al. 2003; Pearson 2004; Andolfatto 2005; Pollard et al. 2006; The ENCODE Project Consortium 2007), and it is being suggested that much of the junk DNA may be regulatory genes (Check 2006). A summary of a massive literature on non-coding DNA reveals that the percent of the genome that is non-coding is directly proportional to the structural complexity of the organism, implying that it has a function in generating that complexity (Fig. 2) (Mattick 2004). If this trend continues, it may be found that much more DNA is involved in regulation than has been recognized.
This doesn’t demonstrate that there are no extra copies of genes. However, it is clear that a vast complex of genes is needed to regulate when and where each protein will be made and in what quantity, the embryological development of each different organ and its integration with other organs, the functioning of the tremendously complex biochemical systems in each cell, and controlling such things as how long your fingers will be. Until we know where all these regulatory genes are, it is naive to talk about junk DNA. It is also not clear whether the multitude of duplicated genes needed for megaevolution (the presumed evolution of new gene complexes, new structures, or new body plans; see Brand 1997, 2006) actually exist.
Even if those duplicate genes do exist, the critical question I have referred to still must be answered. In all naturalistic theories any new genetic information can enter the genome only through random mutations.
Figure 2. The relationship between amount of “junk DNA” (non-coding DNA) and the structural complexity of organisms (after Mattick 2004).
The usual response is that although mutations are random, natural selection is not a random process; it selects beneficial features and rejects detrimental ones. This is true, but selection can act only on the raw material that mutation provides for it, and mutation is a random process in the sense that it does not know the needs of the organism, or what those needs will be in the future. If new information is to enter the genome, the needed mutations must 1) occur by chance when they are needed, and 2) they must result in some selective advantage for the organism at each step along the way, or they will be eliminated by selection or further random mutations. Unless these two conditions are met, natural selection is powerless to make anything new and useful. This is not a minor problem.
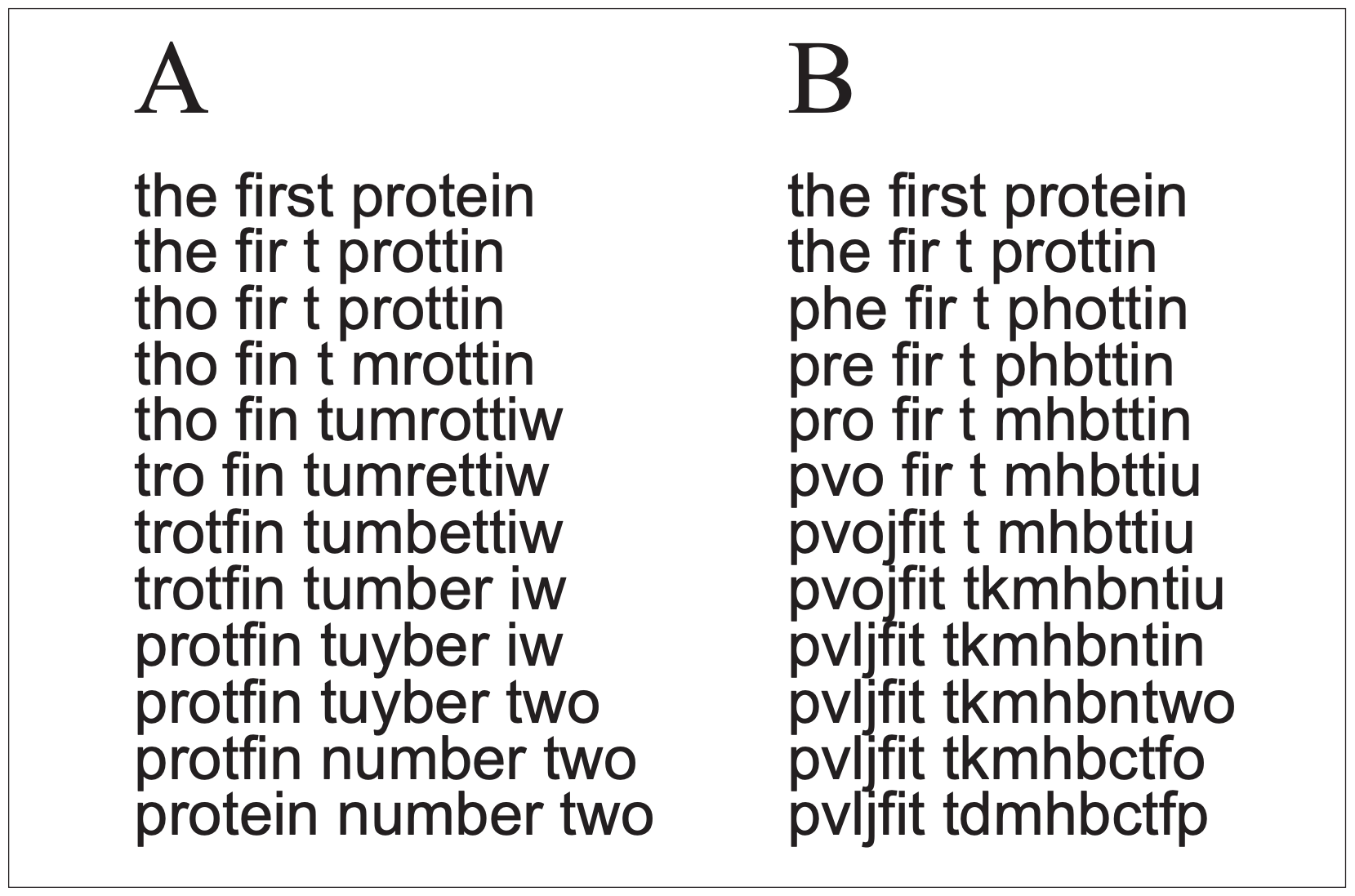
Figure 3 illustrates this point. If a gene that produces a protein with a specific function is duplicated, and the duplicate is to change until it produces a new protein with a different function, new to the organism, a series of mutations will be needed to alter it to the new form (we will ignore for now the complex of regulatory genes needed to make the new gene functional). The sequence in Fig 3A is just like Dawkins’ weasel analogy — successful evolution of the new gene if each step is favored by natural selection, working toward a known target. But natural selection doesn’t work that way. Figure 3B is more like reality, with a sequence of truly random mutations, governed by chance. In this process the chances that needed mutations will be the ones to be preserved is far lower than the chance that mutations will cause the nucleotide sequence to wander randomly through time and make nothing useful. Percent of DNA not coding for protein
If selection is involved (as in Fig. 3A), there is a big problem if the protein must go through a stage that is nonfunctional or with reduced function (which is highly likely) before achieving the new function. The problem is that selection does not know anything about the future new function, but at each step along the way will eliminate gene forms that are reduced in their ability to carry out the old function (the middle steps in Fig. 3A). In this case neither 3 A or B will be favored; the preservation of the original gene will be favored over any change. These problems will come into play at every step of any proposed evolution of new genes, new proteins and new structures that did not exist before (as in every step in the presumed evolution of different types of eyes).
Figure 3. Two series of mutations, using letters to symbolize nucleotides in DNA, with a meaningful phrase representing a functional protein. There are two mutations in each step, except one mutation in the last step in (A). In (A) a series of mutations converts one gene into a new gene producing a protein with a different function. Almost all mutations make a positive alteration toward the new gene. Example (B) is a series of truly random mutations. Some mutations are constructive changes toward the new gene, but unless the new gene is already functional and selected for, those constructive changes are just as likely to change again, away from the “goal”. Evolution of a new gene and protein would involve many more mutations, but the principle would be the same: example (B) is a far more probable series of events.
This is the major challenge faced by naturalistic megaevolution theory — the critical question I have referred to. There doesn’t seem to be convincing evidence to support the theory of duplicate genes evolving into new genes with a new function. The evolution literature generally relies on just-so stories that assume the needed new information will appear when needed.
ID and megaevolution
The challenges raised by ID are not only pertinent to the origin of life, but also to discussion of the origin of new organisms which exhibit a new body plan with new structures, systems and genes. Behe’s examples of irreducible complexity include flagella and the blood clotting system. These would not be present in the initial living cells, but appear in more complex organisms. Such a level of change is megaevolution.
It is often claimed that if the small changes (microevolution) occur, the same process, given enough time, will produce the larger changes in body plans. But evolving a new body plan is very different from microevolution and speciation. Microevolution involves variation in the alleles of existing genes, but does not seem to require significant new biological information in the form of new complexes of structural and regulatory genes and their resulting proteins. By the term significant I am making a difference between producing variations of an existing protein, e.g., hemoglobin (microevolution), and the production of a whole new complex of genes and proteins — for example the complicated system needed for live birth in mammals (megaevolution).
The hypothesis that the small changes observed in microevolution will extrapolate into production of the large changes needed for megaevolution is an assumption. In the evolution literature it is generally assumed that there is no difference in the process of microevolution and the process of megaevolution; the small changes will naturally add up to the largest evolutionary changes. There are two primary lines of evidence often considered as demonstration that this is more than an assumption. One of these is homology — the homologies that are used to develop phylogenetic hypotheses. All mammals, reptiles and amphibians have front limb skeletons with a scapula, humerus and ulna, carpals, metacarpals and phalanges. These skeletal similarities are homologies. Homologous features are interpreted as evidence that the organisms possessing them evolved from a common ancestor.
The Mesozoic bird Archaeopteryx has certain homologies in bone structure with dinosaurs, and this is considered to be evidence that they evolved from common ancestors (Ostrom 1994; Gishlick 2004). The same concept applies to homologies in biochemistry, including homologous genes. But of course if life was intelligently designed, some homologous features could have resulted from common design, by a designer who designs in an organized, systematic way, employing a common principle of engineering design: reusing components that perform a given function well. In this view of biology, it would take careful study to differentiate between “homologies” that resulted from common design, and true evolutionary homologies that resulted from descent with modification within designed, independently originated groups.
Futuyma (2005) also discusses new gene origin by exon shuffling, producing new combinations of protein domains. But this process could be part of the original created mechanism for generating genetic variation (Wood 2002). If life was not created, there would be definite limits to how much genetic novelty could arise through this process, until new domains evolved by gene duplication and mutation. Thus exon shuffling as a source of the new genes needed for megaevolution is subject to the same constraints discussed above for gene duplication.
The other line of evidence that new genes can evolve comes from observed modern events like evolution of insect resistance to pesticides, bacterial resistance to antibiotics, or appearance of new enzymes in bacterial cultures. Spetner (1998), in his book Not by Chance, analyzes the molecular details in these phenomena. He found that no point mutation known at that time has added any new genetic information. For example, a bacterium that developed resistance to streptomycin did so because a mutation changed the ribosome protein where the streptomycin attaches, making the protein less specific, which means loss of genetic information, not gain of information. This loss of specificity has side effects, making the ribosome less efficient. Thus resistance to a deadly drug was “bought” at the price of a less effective ribosome. This type of change cannot produce the new genetic information needed for megaevolution. Other examples of known mutations followed the same principle.
Barry Hall (1982, 1988) studied changes in a strain of bacteria that some others have interpreted as the evolution of a new enzyme. Hall prepared a strain of bacteria with a mutation that destroyed its ability to break down lactose. Then two other mutations occurred and a new enzyme appeared that could utilize lactose. However, these two mutations appeared in many cultures within a few days, which indicates that it was not a new enzyme, but just the activation of an already existing gene and its enzyme, whenever the conditions were right (Spetner 1998; Behe 2001).
Spetner’s analysis supports the conclusion that there is no evidence that random mutations can produce truly new genetic information. If this is true, then there is no known genetic mechanism to produce megaevolutionary change. Perhaps new research will modify this conclusion some, but that remains to be seen. Also, for megaevolution to be a viable process to generate the diversity of life on earth there needs to be more than a slight possibility of evolving new genetic information. There would need to be a reliable process to generate a rich input of new information on a regular basis. So far the evidence for this has not been forthcoming. This is the critical question that has arisen several times in this essay. Many of the anti-ID arguments we have reviewed fail unless evidence is found supporting the evolution of biological information.
Of course none of this disproves the theory of megaevolution, because it can be claimed that we just don’t know enough yet to understand how it works. We can’t deny that argument, since all of us, no matter what our view on origins, must exercise considerable faith in our beliefs or theories. One who favors ID has many unanswered questions about the designer. And a materialistic view requires strong faith that this theory will someday answer the unknowns as to how genetic information and molecular complexity arose. Personally, I predict that in future centuries, when we know much more about molecular biology, we will see the theory of life arising without intelligent design as an area of great naiveté in 20th century scientific thinking.
Weber and Depew (2004) say Darwin showed that “natural selection could account for the empirical claim of a common descent for all living beings.” This claim is seriously premature.
The explanatory filter – a logical tool for identifying ID
Dembski (1999, 2002) has described an explanatory filter to identify design and distinguish it from features that could result from chance. He claims that the logic used in his filter is essentially the same as archeologists or forensic scientists would use to determine if some feature resulted from intelligence. The filter involves three logical steps: 1) contingency — could the feature exist in some other form than it has? 2) complexity — is the feature complex enough (by a rigorous quantitative standard) to require design? 3) specification — does it match some specific known pattern (e.g., if it is a protein, does it work)?
Gary Hurd (2004) compares the explanatory filter with the logical procedures used in archeology and forensic science and concludes that the explanatory filter does not match what an archeologist or forensic scientist does. Some of his criticisms miss the point of the filter. For example the filter could probably not distinguish whether certain events were suicide, murder, or divine retribution, because all three of those explanations are the result of intelligent action. Most of Hurd’s examples are of this same type. However, he seems to make a valid point that archaeologists and forensic scientists don’t use Dembski’s filter in their work. Perhaps the filter is best described as a type of logic that may underlie some of the actual procedures used in archeology and forensics, but they don’t use the filter as such.
ID and publishing
It is often claimed by critics that ID advocates don’t publish in peerreviewed journals, revealing that their ideas about ID are not really science. Stephen Meyer did publish an article making the case for ID in a local peer-reviewed journal, the Proceedings of the Biological Society of Washington (Meyer 2004), entitled “The origin of biological information and the higher taxonomic categories.” His article discussed various scientific difficulties in evolution by natural selection, and in explaining the origin of many phyla in the Cambrian explosion. Meyer explains that because intelligent agents are the only known cause for specified complexity, as found in biological systems, intelligent design is the best explanation for the origin of biological information. Most scientists continue to use MN to seek answers to these challenges, but Meyer suggests that the evidence points to design of living things.
The Biological Society of Washington was severely scolded by the scientific community for publishing this article (Giles 2004; Helgen 2004; Ligon & Lovern 2004; Terry 2004), and the society published a statement repudiating the Meyer paper and its ID concept and describing irregularities in the editorial process that allowed the paper to be published. The article was peer-reviewed, but it is claimed that the editor, an ID sympathizer, didn’t utilize all the other quality control processes of the journal.
The Meyer article was a thoughtful presentation of the topic, but most of the responses failed to respond to the arguments in the paper. They only argued that it was not legitimate for such a paper (not in accord with MN) to be published in a scientific journal. To criticize ID proponents for not publishing can only have validity if journals accept articles on the merits of their content, and not according to whether the articles are based on acceptance of MN.
ID and Philosophy
Neither the proponents nor the opponents of ID have so far produced arguments that are convincing to the other side. This is partly because of the complexity of the biochemical phenomena they are arguing about. Both sides will likely continue to hone their arguments. But there is one major difference. ID recognizes and focuses on the real issue — the origin of biological information, while their critics skirt this issue and base their criticisms of ID on peripheral issues. The critics of ID rely on the assumption that the biological information will evolve when needed, using word pictures to support their arguments. In reality, the argument can probably never be resolved as long as the philosophical incompatibility between the two groups exists. The concepts of ID could never be accepted, no matter how true they may be, as long as there is a commitment to MN.
It is claimed that ID is being rejected as unscientific, not only because of philosophy, but because it hasn’t been successful in generating new, publishable scientific research. This is, so far, largely true, for various reasons. I suggest that there is much more promise for such research than has yet been realized.
However, ID does ask legitimate questions about the nature of the search for truth. Since MN is not a scientific claim, but is a philosophy, to reject ID because it is a violation of MN is a philosophical or religious choice, not a scientific choice. Even if ID doesn’t succeed in initiating many testable hypotheses, the claims of ID still could be true. For science to try to keep ID from being discussed may be just as unproductive as it was for the church in Galileo’s day to try to prevent open discussion of the heliocentric universe theory. A valid intellectual goal of ID is to put naturalism out on the table for open discussion, and it has made considerable progress toward this goal, even though it is vigorously opposed by many prominent scientists.
One criteria for determining the scientific value of a theory is whether it can make predictions testable by empirical evidence. To some extent it will be hard for ID to make specific predictions, for the same reason it is hard to predict just what evolutionary adaptation will result from some environmental change. When we are investigating the unknown we will often not know, ahead of time, what to look for. However, there are definite predictions that ID can make. ID predicts that when we fully understand life, we will find sophisticated, fully functional systems everywhere. Thus those parts and systems that naturalistic science describes as poorly designed, or “cobbled together” by evolution, will be especially fruitful subjects for study, because the full design of those systems has not yet been discovered. The expectations of design encourages detailed study of such systems, because the reward will often be significant discoveries of new phenomena.
In the early 1970’s some ID-oriented molecular biologist friends of mine were predicting that so-called junk DNA will be found to be functional. That prediction is now beginning to be verified. Also, for many years evolutionary biologists have described the vertebrate retina as a poorly designed evolutionary accident, because the cell layers are arranged backwards; the light must pass through several cell layers before reaching the photoreceptors. A recent paper (Franze et al 2007) reports a reexamination of the retina. I don’t know whether the authors favor ID, but their research is exactly the type of research that ID can stimulate. It was found that the Müller cells in the retina have unique and unexpected properties. They are actually living optical fibers that transmit light through the outer cell layers and to the photoreceptors with very high efficiency. Rather than being an inefficient evolutionary accident, the retina is a highly efficient, very sophisticated design.
CONCLUSION
Shallit and Elsberry (2004) make an amazing statement — “Dembski thinks intelligence has a magical power that permits it to do something that would be impossible through natural causes alone.” But if intelligence confers no advantage, why do we invest energy in science and technology? Why haven’t we just waited for natural causes to heat our houses, cure diseases, and provide the conveniences that enhance our lives? Of course Shallit and Elsberry are referring specifically to the origins process, but my response still stands. The inventive power of intelligence can accomplish unimaginably more than unaided natural causes, and since intelligence has the qualities that can explain the complexity of life, why not allow it to be considered as an explanatory cause? The authors I have cited have not provided evidence to contradict that conclusion, as long as we are willing to consider naturalistic theories of origin as hypotheses to be tested, rather than truth by fiat.
The debate over origins gets more complicated all the time, and is not likely to end any time soon. ID proponents like Behe and Dembski have presented interesting challenges to naturalism, but their detractors suggest many detailed reasons why ID concepts like irreducible complexity or complex specified information are not problems for the evolution process. The ID side then presents answers to these arguments, but it doesn’t seem that either side is able to produce arguments convincing to the other side. They are arguing about complex things, and hypotheses of presumed events from the past that can’t be directly tested. It is very hard to find “silver bullet” arguments on these issues! But that is not the real problem.
Ultimately it remains a philosophical argument. For those scientists who accept MN as part of the definition of science, no argument that appeals to an intelligent cause to explain life, no matter how accurate, will be satisfactory. For them, accepting the possibility of a design explanation for any event or phenomenon means throwing in the towel and stopping the scientific search for answers in that topic.
And in some cases that may be correct, because if life did not begin by a naturalistic process, there is little for science to study about life’s origin. But knowing that life began by design could prevent much pointless research on abiogenesis (naturalistic origin of life) and redirect that scientific effort to some other, more productive area.
On the other hand, many persons are more interested in seeking the truth about our origin and destiny than in choosing ideas simply because they generate new scientific hypotheses. And for those who reject naturalism, or are willing to at least consider some form of design, the most sophisticated biological arguments against ID, will probably not be convincing, for several reasons. First, most anti-ID arguments are based on the prior acceptance of naturalism, making them circular arguments against ID. Second, most substantial anti-ID arguments are actually attempts to show that plausible theories for origins without a designer can be proposed, rather than an evenhanded evaluation of ID vs. naturalistic origins. And third, many of the anti-ID arguments are, on purely empirical grounds, not convincing. They have little impact because they are just unsubstantiated word pictures.
Those who accept MN as part of the definition of science will reject arguments for ID because that idea is ruled out, by definition, by MN, as a part of science.
It is probably not possible to scientifically refute either the hypothesis that the first life forms were invented and put together by a designer, or that spontaneous generation of life occurred. It also appears that science has not produced convincing evidence in support of the most critical issue for origin by naturalistic processes — the origin of biological information without intelligent input. It has been argued that theories of origin by design are immune from disconfirmation. That may be true, but for many scientists the concept of naturalism is also immune, by choice, from disconfirmation, and too much dependence on naturalism and deep time to solve any theoretical problem can lead to careless reasoning. A number of anti-ID arguments cited in this paper are evidence of this.
The cause of all the heated controversy, the thorny issue of what should be taught in public schools, is quite dependent on what definition is accepted for science, and at present MN is at the center of that definition.
Some of us wish primarily for one thing — that science be an openminded search for truth, and not a game defined by any one philosophical position on intelligence or materialism. Individual scientists may prefer one or the other philosophy, but if scientists with different views can talk to each other, with respect rather than condescension, and even work together, we can make progress in our understanding of both scientific issues and religious perspectives.
REFERENCES
Adami C. 2006. Reducible complexity. Science 311:61-63.
Andolfatto P. 2005. Adaptive evolution of non-coding DNA in Drosophila. Nature 437:1149-1152 (see also comment on p xi).
Behe MJ. 1996. Darwin’s Black Box: The Biochemical Challenge to Evolution. NY: The Free Press.
Behe MJ. 2000. Self-organization and irreducibly complex systems: a reply to Shanks and Joplin. Philosophy of Science 67:155-162.
Behe MJ. 2001. A response to reviews of Darwin’s Black Box: the biochemical challenge to evolution. Biology and Philosophy 16:685-709.
Behe MJ. 2004. Irreducible complexity: obstacle to Darwinian evolution. In: Dembski WA, Ruse M, editors. Debating Darwin: From Darwin to DNA, p 352-370. Cambridge: Cambridge University Press.
Behe MJ. 2007. The Edge of Evolution. NY: Free Press.
Brand LR. 1997. Faith, Reason, and Earth History: A Paradigm of Earth and Biological Origins by Intelligent Design. Berrien Springs, MI: Andrews University Press.
Brand LR. 2006. Beginnings: Are science and Scripture partners in the search for origins? Nampa, ID: Pacific Press Publishing Association.
Bridgham JT, Carroll SM, Thornton JW. 2006. Evolution of hormone-receptor complexity by molecular exploitation. Science 312:97-101.
Check E. 2006. It’s the junk that makes us human. Nature 444:130-131.
Dawkins R. 1986. The Blind Watchmaker. NY: W.W. Norton & Company.
Dembski WA. 1998. Mere Creation: Science, Faith and Intelligent Design. Downers Grove, IL: InterVarsity Press.
Dembski WA. 1999. Intelligent Design: The Bridge Between Science and Theology. Downers Grove, IL: InterVarsity Press.
Dembski WA. 2002. No Free Lunch: Why Specified Complexity Cannot be Purchased Without Intelligence. NY: Rowman and Littlefield Publishers.
Dembski WA. 2004. The Design Revolution: Answering the Toughest Questions about Intelligent Design. Downers Grove, IL: InterVarsity Press.
Dembski WA, editor. 2006. Darwin’s Nemesis: Phillip Johnson and the Intelligent Design Movement. Downers Grove, IL: InterVarsity Press.
Dembski WA, Kushiner JM, editors. 2001. Signs of Intelligence: Understanding Intelligent Design. Grand Rapids, MI: Brazos Press.
Dembski WA, Ruse M. 2004. Debating Design: From Darwin to DNA. Cambridge: Cambridge University Press.
Dembski WA, Wells J. 2008. The Design of Life. Dallas, TX: The Foundation for Thought and Ethics.
Denton M. 1985. Evolution: A Theory in Crisis. Bethesda, MD: Adler and Adler. Edis T. 2004a. Grand themes, narrow constituency. In: Young M, Edis T, editors, Why Intelligent Design Fails, p 9-19. New Brunswick, NJ: Rutgers University Press.
Edis T. 2004b. Chance and necessity — and intelligent design? In: Young M, Edis T, editors, Why Intelligent Design Fails: A Scientific Critique of the New Creationism, p 139-152. New Brunswick, NJ: Rutgers University Press.
Franze K, and 9 others. Müller cells are living optical fibers in the vertebrate retina. Proceedings of the National Academy of Sciences (USA) 104:8287-8292.
Futuyma DJ. 2005. Evolution. Sunderland, MA: Sinauer Associates, Inc.
Gibson LJ. 1994. Pseudogenes and origins. Origins 21:91-108. (grisda.org)
Giles J. 2004. Peer-reviewed paper defends theory of intelligent design. Nature 431:114.
Gishlick AD. 2004. Evolutionary paths to irreducible systems: the avian flight apparatus. In: Young M, Edis T, editors, Why Intelligent Design Fails: A Scientific Critique of the New Creationism, p 58-71. New Brunswick, NJ: Rutgers University Press.
Gould SJ, Vrba ES. 1982. Exaptation: a missing term in the science of form. Paleobiology 8:4-15.
Hall BG. 1982. Evolution in a Petri dish: the evolved ß-galactosidase system as a model for studying acquisitive evolution in the laboratory. Evolutionary Biology 15:85-150.
Hall BG. 1988. Adaptive evolution that requires multiple spontaneous mutations. I. Mutations involving an insertion sequence. Genetics 120:887-897.
Haught JF. 2004. Darwin, design, and divine providence. In: Dembski WA, M. Ruse M, editors, Debating Darwin: From Darwin to DNA, p 229-245. Cambridge: Cambridge University Press.
Helgen KM. 2004. Meyer paper: don’t hang the Soc. Wash. out to dry. Nature 432:949.
Hirotsune S. and 8 others. 2003. An expressed pseudogene regulates the messenger-RNA stability of its homologous coding gene. Nature 423:91-96 (see also comment on p 26-28).
Hurd GS. 2004. The explanatory filter, archaeology, and forensics. In: Young M, Edis T, editors, Why Intelligent Design Fails, p 107-120. New Brunswick, NJ: Rutgers University Press.
Johnson PE. 1991. Darwin on Trial. Downers Grove, IL: InterVarsity Press. Johnson PE. 1995. Reason in the Balance: The Case Against Naturalism in Science, Law and Education. Downers Grove, IL: InterVarsity Press. Johnson PE. 1997. Defeating Darwinism by Opening Minds. Downers Grove, IL: Inter-Varsity Press.
Johnson PE. 2000. The Wedge of Truth: Splitting the Foundations of Naturalism. Downers Grove, IL: InterVarsity Press.
Ligon DB, Lovern MB. 2004. Meyer publication worse than just bad science. Nature 432:949.
Martin AJ. 2001. Introduction to the Study of Dinosaurs. Malden, MS: Blackwell Science. Mattick JS. 2004. The hidden genetic program of complex organisms. Scientific American (Oct.):60-67.
Meyer SC. 2004. The origin of biological information and the higher taxonomic categories.
Proceedings of the Biological Society of Washington 117:213-239. Meyer SC, Mimich S, Moneymaker J, Nelson PA, Seelke R. 2007. Explore Evolution.
Melbourne, Australia: Hill House Publishers. Miller KC. 1999. Finding Darwin’s God: A Scientist’s Search for Common Ground Between God and Evolution. NY: HarperCollins Publishers.
Miller KC. 2004. The flagellum unspun: the collapse of “irreducible complexity.” In: Dembski WA, Ruse M, editors, Debating Darwin: From Darwin to DNA, p 81-97. Cambridge: Cambridge University Press.
Musgrave I. 2004. Evolution of the bacterial flagellum. In: Young M, Edis T, editors, Why Intelligent Design Fails: A Scientific Critique of the New Creationism, p 72-84. New Brunswick, NJ: Rutgers University Press.
Norell M, Ji Q, Gao K, Yuan C, Zhao Wang YL. 2002. ‘Modern’ feathers on a non-avian dinosaur. Nature 416:36-37.
Nowak R. 1994. Mining treasures from “junk DNA.” Science 263:608-610. Ochert A. 1999. Transposons: so-called junk DNA proves its worth: first in corn, now in creatures like us. Discover Genetics 20 (12):59-66.
Ostrom JH. 1994. On the origin of birds and of avian flight. In: Prothero DR, Shoch RM, editors, Major Features of Vertebrate Evolution, p 160-177. Short Courses in Paleontology, No. 7. The Paleontological Society.
Pennock RT. 2003. Creationism and intelligent design. Annual Review of Genomics and Human Genetics 4:143-163.
Pennock RT. 2004. DNA by design? Stephen Meyer and the return of the god hypothesis. In: Dembski WA, Ruse M, editors, Debating Darwin: From Darwin to DNA, p 130148. Cambridge: Cambridge University Press.
Pearson H. 2004. ‘Junk’ DNA reveals vital role. Nature Science Update, May 10. www.nature.com/nsu/040503/040503-9.html.
Perakh M. 2004. There is a free lunch after all: William Dembski’s wrong answers to irrelevant questions. In: Young M, Edis T, editors, Why Intelligent Design Fails: A Scientific Critique of the New Creationism., p 153-171. New Brunswick, NJ: Rutgers University Press.
Pollard KS, and 15 others. 2006. An RNA gene expressed during cortical development evolved rapidly in humans. Nature 443:167-172 (see also comment on p 149-150).
Ratzsch D. 2001. Nature, Design and Science: The Status of Design in Natural Science. Albany, NY: State University of New York Press.
Reynaud C, Dahan A, Anquez V, Weill J. 1989. Somatic hyperconversion diversifies the single VH gene of the chicken with a high incidence in the D region. Cell 59:171-183.
Scott EC. 2004. Evolution vs. Creationism: An Introduction. Westport, CT: Greenwood Press.
Shallit J, W. Elsberry W. 2004. Playing games with probability: Dembski’s complex specified complexity. In: Young M, Edis T, editors, Why Intelligent Design Fails: A Scientific Critique of the New Creationism, p 121-138. New Brunswick, NJ: Rutgers University Press.
Shanks N, Joplin KH. 2007. Behe, biochemistry, and the invisible hand. Philo 4(1):1-16. http://www.philoonline.org/library/shanks 4 1.htm
Shanks N, Karsai I. 2004. Self-organization and the origin of complexity. In: Young M, Edis T, editors, Why Intelligent Design Fails: A Scientific Critique of the New Creationism, p 85-106. New Brunswick, NJ: Rutgers University Press.
Shanks N, Joplin KH. 1999. Redundant complexity: a critical analysis of intelligent design in biochemistry. Philosophy of Science 66:268-298.
Spetner L. 1998. Not by Chance! Shattering the Modern Theory of Evolution. Brooklyn, NY: The Judaica Press.
Thaxton CB, Bradley WL, Olsen RL. 1984. The Mystery of Life’s Origin: Reassessing Current Theories. NY: Philosophical Library.
The ENCODE Project Consortium. 2007. Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project. Nature 447:799-816.
Terry M. 2004. One nation, under the designer. Phi Delta Kappan December 2004:264270.
Ussery D. 2004. Darwin’s transparent box: the biochemical evidence for evolution. In: Young M, Edis T, editors, Why Intelligent Design Fails: A Scientific Critique of the New Creationism, p 48-57. New Brunswick, NJ: Rutgers University Press.
Weber BH, Depew DJ. 2004. Darwinism, design, and complex systems dynamics. In: Dembski WA, Ruse M, editors, Debating Darwin: From Darwin to DNA, p 173-190. Cambridge: Cambridge University Press.
Wood TC. 2002. The ageing process: rapid post-flood intrabaraminic diversification caused by altruistic genetic elements (AGES). Origins 54:5-34. (grisda.org)
Young M. 2004. Grand designs and facile analogies: exposing Behe’s mousetrap and Dembski’s arrow. In: Young M, Edis T, editors, Why Intelligent Design Fails: A Scientific Critique of the New Creationism, p 20-31. New Brunswick, NJ: Rutgers University Press.
Young M, Edis T, editors. 2004. Why Intelligent Design Fails: A Scientific Critique of the New Creationism. New Brunswick, NJ: Rutgers University Press.