Por el Dr. Timothy G. Standish
Una revolución está ocurriendo en la manera cómo se entienden los genomas de los organismos. Uno de los progresos más sorprendentes es el inesperado hallazgo de que el número de genes en los genomas es pequeño. Se pensaba que un genoma que codificara para algo tan complejo como un ser humano debería estar constituido por unos 100.000 genes;1 o quizá más. Sin embargo, desde la publicación del genoma humano2 parece como si los humanos tuvieran casi el mismo número de genes que los organismos más simples –como los gusanos nematodos– probablemente menos de una cuarta parte de las estimaciones anteriores.
Esta nueva idea acerca del número de genes en los genomas ha agravado un problema que ya fue presentado por la anterior generación de científicos: si hay tan pocos genes, ¿por qué los seres humanos y muchos otros organismos tienen tanto ADN en sus genomas? Se decía que solamente el 3% de los 3 mil millones de nucleótidos en el genoma humano codificaba realmente para producir proteínas. Así, la mayoría de nuestro genoma codificaba para nada, o al menos eso parecía. Este ADN que no codifica proteínas fue calificado con rechazo como “ADN basura”, y algunos prominentes Darwinistas y sus seguidores se subieron al carro del “ADN basura” afirmando que era exactamente lo que predice el proceso de evolución darwiniana.3 Aunque mejor, pero de ninguna manera cerca de ser completo, el conocimiento de los genomas ha aumentado y los genomas parecen ser mucho más elegantes de lo que originalmente se apreció y se predijo por algunos Darwinistas. Este evidente diseño en los genomas se puede acomodar de la misma manera que son acomodados por el Darwinismo los otros indicios de diseño, llamándole diseño “aparente” más bien que diseño verdadero. No obstante, el descubrimiento de función en el “ADN basura” cuestiona la contribución más importante de Richard Dawkins a la teoría evolutiva, la hipótesis del “gen egoísta”.4 Además, las explicaciones naturalistas parecen menos capaces de explicar los sistemas de control en los genomas que los productos de los genes en forma de proteínas. Si el Darwinismo explica la funcionalidad del “ADN basura” del mismo modo que explica la carencia de función en el ADN, entonces es razonable concluir que por lo menos en algunos casos tanto predice todo como explica nada.
Uno de las preguntas más importantes que surgen del asombrosamente pequeño número de genes en seres humanos y otras criaturas “más elevadas” es, ¿de dónde proceden todas las proteínas? De acuerdo con la vieja idea sobre los genes, cada gen codifica una proteína. Éste es el concepto de “un gen, una enzima” por el cual Beadle y Tatum recibieron el premio Nobel en medicina en 1958.5 Debido a que los seres humanos producen más de 100.000 proteínas y parece haber menos de 25.000 genes,6 al menos algunos genes deben ser capaces de producir más de una sola proteína. Un mecanismo para hacer esto es similar al mecanismo que se conoce para la generación de las proteínas de la inmunoglobulina (los anticuerpos).7 En este mecanismo, ciertos segmentos diferentes del ADN que codifica proteínas se pueden ensamblar juntas de diversas maneras para hacer literalmente miles de millones de proteínas diversas de anticuerpos. Se sabe que algunos mecanismos similares operan en otros genes, aunque no se conoce ninguno que sea capaz de producir los millones de variaciones logradas por el sistema genético que genera los anticuerpos.
La mayoría de los genes en los seres humanos y otros eucariotas (así como algunos genes en procariotas) se componen de segmentos de ADN llamados “exones” separados por segmentos llamados “intrones”. Cuando se va a producir una de las proteínas codificadas por el gen, lo primero es hacer una copia (transcripción) del ADN del gen.
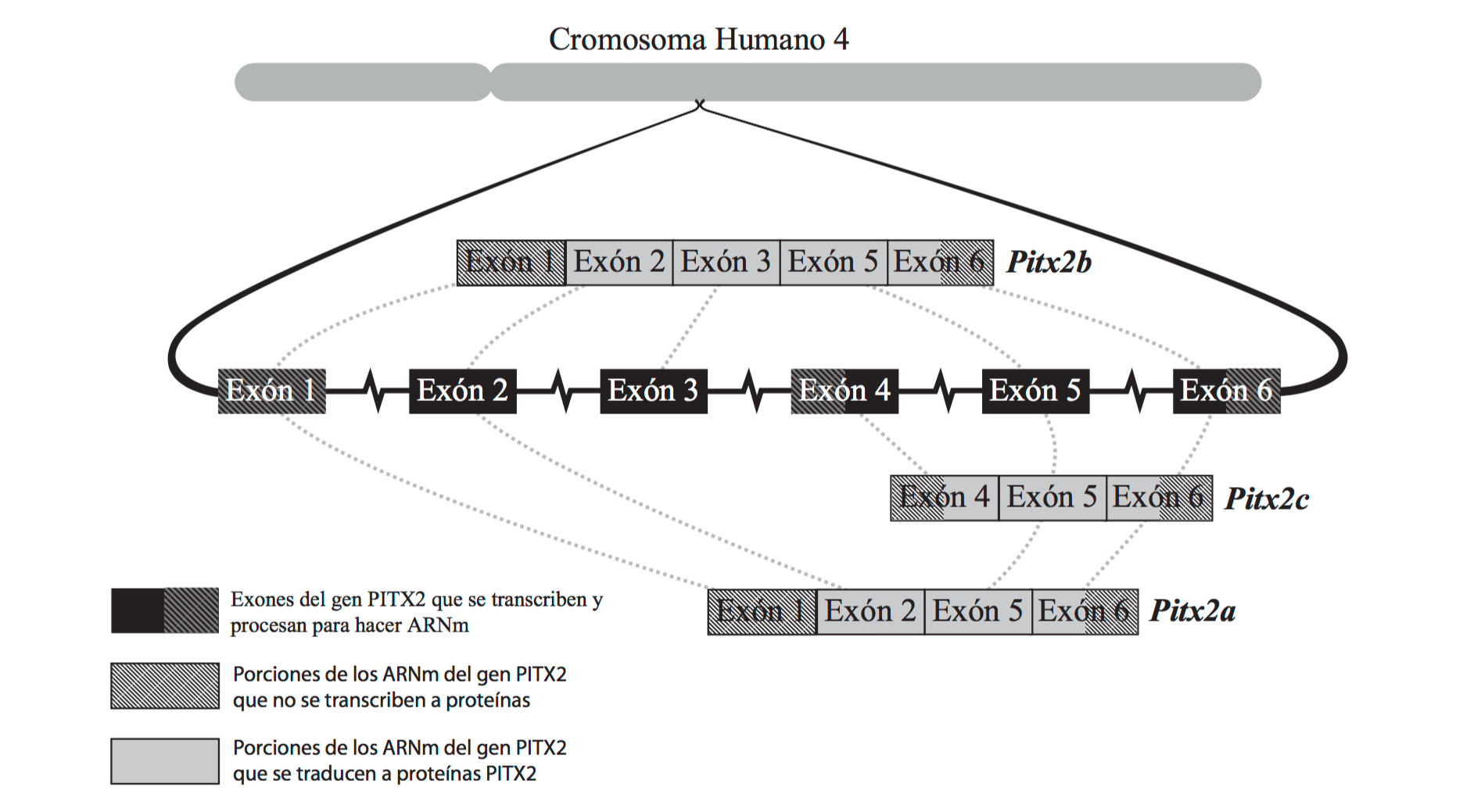
El gen humano PITX2 se compone de 6 exones separados por 5 intrones. Se obtienen varias proteínas de este mismo gen al ensamblar diferentes exones que se expresan en ARN transcritores de PITX2 con puntos de inicio de transcripción y traducción diferentes. En esta ilustración, los exones e intrones no están representados a escala. En el gen real, los exones varían significativamente en tamaño y los intrones componen la mayor parte del gen. Los ARMm para PTIX2A, B y C se muestran después de haber eliminado los intrones y el ARN.
Entonces este ARN transcripto se procesa para quitar los intrones y ensamblar los exones contiguamente en una molécula de ARN mensajero (ARNm). Es el ARNm el que lleva la información fuera del núcleo de la célula a las factorías productoras de proteínas llamadas ribosomas, las cuales traducen la información del ARNm a una proteína específica. El ensamblaje de diferentes exones permite la formación de diversos ARNm resultando en la producción de una diversidad de proteínas.
El gen PITX2 del ser humano ilustra cómo funciona el procesamiento del ARNm para crear varias proteínas diferentes a partir de un solo gen. PITX2 está compuesto de seis exones separados por cinco intrones (Figura 1). Al juntar los exones 1,2, 5 y 6, se crea el ARNm para una versión del PITX2 llamado “IsoformaA”, o PITX2A. Al juntar los exones 1,2,3,5 y 6 se hace el ARNm para el PITX2B, y los exones 4, 5 y 6 codifican para el PITX2C. La proteína resultante del PITX2 desempeña un papel en el desarrollo adecuado de la cabeza, los ojos y otros órganos por medio de su unión al ADN y la influencia sobre la producción de otros genes.8 El terminal C del PITX2 que se une al ADN está codificado en los exones 5 y 6, de modo que todas las formas de PITX2 se unen a ADN. 9 Si se cambian ciertas partes de la proteína hacia el terminal N del gen eso presumiblemente impactará la manera como el PITX2 interacciona con otras moléculas.10
Las variaciones de la proteína del PITX2 son en realidad más complejas que esto. Mientras que las isoformas A, B y C están ampliamente distribuidas entre los animales vertebrados, una cuarta variación, PITX2D, sólo se encuentra en humanos.11 Tanto el PITX2C como el D están hechos de un ARN transcripto que comienza en medio del gen del PITX2, pero en el ARNm del PITX2D se elimina una porción del exón 4 juntamente con el intrón 3. Existen otras variaciones de la proteína PITX2 que no han sido mencionadas aquí. La idea de este ejemplo es que un único gen puede ser usado para hacer múltiples proteínas. Si ese es el caso, entonces es necesario que existan mecanismos regulatorios para asegurarse de que las proteínas adecuadas sean sintetizadas por los genes apropiados.
¿Que tiene que ver esto con el “ADN basura”? El reciente avance en el conocimiento de lo que es el gen muestra que el genoma y los genes mismos son mucho más dinámicos de lo que inicialmente imaginábamos. Mientras los genes son menos numerosos de lo que se esperaba, son muy complejos en su estructura, expresión y sistemas de control asociados. La información que controla como se expresan ha de proceder de alguna otra parte. Parte de la información parece estar incluida en los genes mismos, pero gran parte parece yacer fuera de los genes en el ADN considerado como basura resultante del proceso de evolución. Para la sorpresa de muchos, gran parte de lo que una vez fue rechazado como “ADN basura” ahora juega un papel vital en la función normal de los sistemas genéticos.
En los últimos años el “ADN basura” ha proporcionado un tesoro de información sobre cómo operan los genomas. Los complejos sistemas que ayudan a controlar los exones parecen estar involucrados en secuencias que ocupan al menos un tercio del genoma humano.12 Eso es mucho más que el 3% del genoma humano que hace solo unos años atrás se pensaba que era funcional. Parece que varios fragmentos de ARN de transcripción intervienen en la regulación de cada etapa en la producción de proteínas. Estas cortas cadenas de ARN parecen proceder de todas partes del genoma, no solamente de zonas codificadores de genes. De hecho, se está descubriendo que al menos el 70% del genoma se transcribe en ARN13 y que ambas cadenas de la doble hélice de la molécula de ADN se transcriben, no solamente la cadena que codifica una proteína.14 Uno de los descubrimientos recientes más sorprendentes indica que para la formación del huevo fecundado en ratones es necesario un ARN transcriptor de un pseudogen.15 Los pseudogenes son una forma de “ADN basura” que se pueden dividir en dos clases: procesados y no procesados. Los pseudogenes no procesados parecen ser genes normales que están rotos.16 Los pseudogenes procesados se parecen al ARNm que ha sido transcrito de vuelta a ADN. La mayoría de la gente, tanto si creen que Dios creó los seres humanos como si no, estaría de acuerdo en que los genes rotos no son sorprendentes, y que, si el ARN revirtiese ocasionalmente a ADN, muchos no objetarían siempre que los datos apoyaran la afirmación. El descubrimiento de que estos pseudogenes tienen una función es genuinamente sorprendente para mucha gente familiarizada con ellos y muestra lo mucho que todavía nos queda por aprender. Si los pseudogenes tienen de hecho funciones vitales, entonces cuestionan la lógica usada al invocar los pseudogenes y el “ADN basura” como pruebas de un ancestro común, particularmente entre humanos y simios. Esto también revela la imprudencia de creer que las cosas se basan de alguna manera en lo que pensamos que es cierto acerca del mundo en vez de comprobar lo que observamos para ver si lo que creemos que es verdad tiene en realidad categoría de realidad. Resulta difícil mantener los viejos argumentos contra un Dios creador sabio y bueno basados en la falsa presuposición de que los genomas son sobre todo restos de basura como resultado del proceso de la evolución. Otros argumentos más sutiles se basan en las cantidades de ADN mucho más pequeñas que tanto los creacionistas como los Darwinistas pudieran aceptar que no realizan ninguna función en el genoma. Sin embargo, la presunción de falta de función debe verse siempre con escepticismo. No es que haya razones teológicas para no esperar que existan algunas imperfecciones en los genomas, sino que esta presuposición ha resultado ser incorrecta a gran escala con lo que antes era considerado como “ADN basura.” Las nuevas revelaciones científicas sobre el funcionamiento del genoma inspiran sorpresa y admiración acerca de su diseño. Resulta que los mecanismos de control codificados en el “ADN basura” son tan importantes como los genes que controlan y que los seres humanos, junto con los demás seres vivientes, son en realidad “formidables y maravillosos.” 17
REFERENCIAS
- Lewin 2000. Genes VII. Oxford University Press. P. 75.
- Human Genome Sequencing Consortium. 2001. The sequence of the human genome. Science 291:1304-1351.
- Para una discusión detallada de la historia de este argumento y porqué, desde una perspectiva Darwinista, es débil, ver: Standish G. 2002. Rushing to Judgment: Functionality in Non-Coding or Junk DNA. Origins 53:7-30.
- Dawkins R. 2000. El Gene Egoísta. Salvat Editores,
- Nótese que George Beadle y Edward L. Tatum recibieron cada uno un cuarto del premio Nobel de Medicina y Fisiología en 1958, la otra mitad del premio fue para Joshua Lederberg por sus descubrimientos relacionados con la recombinación genética bacteriana.
- Nótese que a pesar de la publicación del genoma humano, el número de genes en el genoma es todavía una estimación, no un recuento del número real de genes. Estas estimaciones se basan en ciertas presuposiciones que pueden o no ser válidas. Para un ejemplo reciente de la estimación del número de genes partiendo de ciertas presuposiciones evolutivas y que concluy e en un número marcadamente bajo ver: Clamp M, Fry B, Kamal M, Xie X, Cuff J, Lin MF, Kellis M, Lindblad-Toh K, Lander ES. Distinguishing protein-coding and noncoding genes in the human genome. Proceedings of the National Academy of Sciences USA 104(49):19428–19433.
- Susumu Tonegawa recibió el premio Nobel in Fisiología y Medicina en 1987 por descubrir el mecanismo genético responsable de la diversidad de
- Gage PJ, Suh H, Camper SA. 1999. The bicoid-related Pitx gene family in development. Mammalian Genome 10:197-200.
- A medida que se manufacturan las proteínas, los aminoácidos se van agregando a la creciente cadena de péptidos por reacciones de deshidratación entre el grupo carboxilo en el último aminoácido agregado y la amina del aminoácido que es añadido. Esto da lugar a un enlace peptídico. Debido a que los aminoácidos se agregan siempre al extremo de la proteína que tiene un grupo carboxilo, las proteínas crecen por el extremo que tiene una amina al descubierto, extremo llamado el terminal N, creciendo hacia el extremo con el grupo carboxilo, llamado terminal
- Lamba P, Hjalt TA, Bernard 2008. Novel forms of Paired-like homeodomain transcription factor 2 (PITX2): Generation by alternative translation initiation and mRNA splicing. BMC Molecular Biology 9(1):31.
- Cox CJ, Espinoza HM, McWilliams B, Chappell K, Morton L, Hjalt TA, Semina EV, Amendt BA. 2002. Differential Regulation of Gene Expression by PITX2 Journal of Biological Chemistry 277(28): 25001-25010.
- Zhang C, Li W-H, Krainer AR, Zhang MQ. RNA landscape of evolution for optimal exon and intron discrimination. Proceedings of the National Academy of Sciences USA 105(15):5797–5802.
- Pheasant M, Mattick JS. 2007. Raising the estimate of functional human Genome Research 17:1245–1253.
- RIKEN Genome Exploration Research Group and Genome Science Group (Genome Network Project Core Group) y el FANTOM 2005. Antisense Transcription in the Mammalian Transcriptome. Science 309:1564-1566.
- Tam OH, Aravin AA, Stein P, Girard A, Murchison EP, Cheloufi S, Hodges E, Anger M, Sachidanandam R, Schultz RM, Hannon GJ. 2008. Pseudogene-derived small interfering RNAs regulate gene expression in mouse Nature. Publicado en internet el 10 April 2008 doi:10.1038/nature06904
- Los pseudogenes no procesados pueden dividirse en dos Los pseudogenes unitarios son genes individuales que se han inactivado mientras que los pseudogenes duplicados son miembros de las familias de los genes. Mientras que otros miembros de las mismas familias de los genes producen proteínas, los pseudogenes duplicados no. Se interpretan como genes que fueron duplicados y más tarde mutados de modo que ya no poseen ninguna función.
- Salmo 139:14.